
My interview journey which led to an offer to join Google as a Pre-Doctoral Researcher.
An overview
The Pre-Doctoral program at Google has been in the limelight among undergraduate researchers for a few years now(because it is hardly two years old :P). I am lucky enough to be a part of this program for about a few months now. With a lot of queries regarding the interview process, I thought of writing a blog for the following reasons : 1. To help people understand how it will actually go. 2. To set the competing ground even. The Pre-Doctoral Researcher role is a 24-month role designed to give you experience working on challenging problems together with research scientists and engineers in Bangalore before pursuing (or making a decision on pursuing) doctoral research. I believe as an undergrad people hardly would have an idea about pursuing PhD and this program helps you calm your nerves (for a few years at least) and help you get a better understanding if you are built for it.
Right into it - The interview process
The Coding round (Early Jan)
The first round as a part of the interview process is the coding round. It exists to test your basics of coding. Trust me, it is necessary. The architecture used at google as well as the speed at which model experimentations happen requires you to have a basic understanding of coding. When I say basics, it tests you on the very basics of data structures and algorithms and I have seen people not doing it so well and still advancing to the next round. My advice : Don’t worry about it so much. Do your basics from “popular” interview prep platforms and you should be able to crack it.
My experience to put things into perspective : I felt the coding round was simple. I was asked a question which required string manipulation and another which was related to tries and dynamic programming. I was able to get done with it in the first 25 minutes of the interview and spent another 25 minutes understanding what my interviewer actually did. He had actually completed PhD and was working in areas of Bio-Technology and it seemed quite interesting to me tbh that google does research in areas it directly does not work in.It ended with talking about novels and him recommending one. Also to give a little background about me in terms of coding proficiency, I worked as a SDE for a year and I was average at coding in my college, but I did get to the interview process of a SWE@Google a year back.
The more important round - The research round (Late Jan)
The research round tends to be an integral part of your interview process, after all the program revolves around it. Initially you would be asked about an area of research you are interested in and the research round would be focussed on it. The overall structure is to initially know about the research work you have done in your undergrad and then you will be asked a question where you need to incrementally build a solution. It tests your knowledge in the domain you have chosen. I think it is better explained by my experience below…
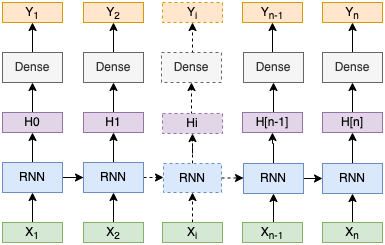
For the research round I was confused about what to choose. I had worked fairly in the field of ML as well as NLP. Eventually I went with NLP because I thought my ML experience was very limited in terms of the latest advancements in the field. So as my interview began, we initially discussed a few projects I had done in my undergrad. He found a few of them very interesting. This was like the first 15 mins of the interview. After this he posed a very simple and standard NLP problem to me. I do not recall it to perfection, but it was something like this : You are given two sequences of equal length : say X and Y. You need to predict Y from X, how would you do it. Here the entries in X have only short term relations. The answer was simple : use a recurrent network and train a prediction network on each of the hidden states. Something like this :
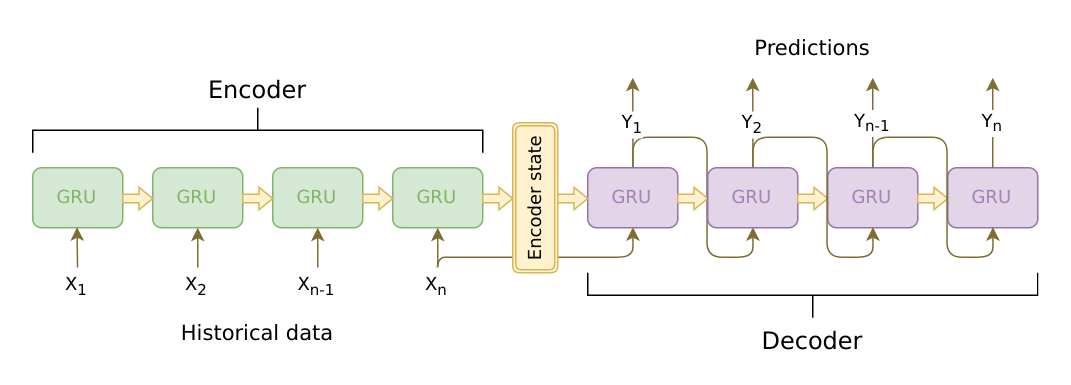
The next complexity was that the length of X and Y are not the same. Again the answer was fairly simple : Use an encoder-decoder based seq2seq model. The architecture being something like this (note that architecture diagrams were asked at every stage) :
The follow up was on the lines of : Now let us assume that apart from lengths not being the same, there are long distance relations between the tokens of A and B which you want to capture. What kind of architecture would you use now! I understood that now the problem was moving towards attention and I explained the problem of vanishing gradients and why we would not be able to use a LSTM and gradually introduced the concept of multi-headed attention and suggested that we can use Transformer blocks as encoders and decoders and further built upon it saying we can use something like BERT to capture Bi-Directional dependencies. Luckily he did not ask for architecture diagrams. (Refer to Attention is all you need for above).
We were running out of time and here was the final question. Assuming that the sequence length is in the order of millions, how would you do the above task. Assume that the relations are not local but also over long lengths. Using attention will not be a good idea because of memory complexity and also local attention is out of the picture. The first and the only thing that came to my mind at that time was highway networks. The basic idea is to train a variable to understand whether to skip the given element while considering the hidden layer output or not. An overall idea is something like this:
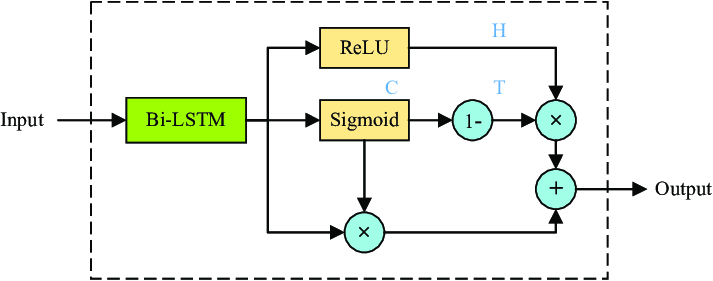
I drew a very rough diagram of this and tried to explain it a bit. The interviewer didn’t seem that happy with the solution, but it was all I could think of. In hindsight now I think that sparse attention or methods of that sort would be what he might be expecting, but overall I felt the interview went average and was not keeping high expectations.
The One after Interviews (Late March/ Early April)
About 2-3 months after giving my interviews there was radio-silence from google recruiters as such. Now I understand the reason, since the research scientists go through our profiles and it takes time. As such I had given up hopes of getting an update and was going on with my normal life. After almost 4 months of the start of my interview process, I had a short interview with my manager. I talked with him, he explained to me a bit about his expectations of me if I join as a PreDoc/RA and we just chatted a bit about my projects and my current work. At that time I had a few restrictions in my previous job so the joining date was something we had a discussion with and then we proceeded with a very normal informal interview kind of thing. He informed me that it would be on Linear Algebra and Probability and tbh I was really unprepared for it but luckily it went well because of good core-ML basics. And this was it : I was finally excited to join PreDoc position at google in August and I was nothing but excited.
My Experience in first three months as a PreDoc
My experience as a PreDoc till now has been nothing but exciting. Firstly I feel lucky to have such a great mentor and a team and the learning factor is 100x. There are a very few basics you miss out when you do research as an undergrad and the program def. gives you an understanding of that. I would say three months are very less to comment on the program as a whole, but there is one thing guaranteed : world class research! Also you get to know a lot of truly genius people and more than that you get to work with them! Initially it might be tough to get ramped up to the speed at which things work here but I feel it is a part of the process. The research life for me personally is a bit more hectic than the SDE life, but it is rather out of interest than compulsion – this is important. I would say if you are someone who is motivated towards research or just want to explore if you are made for it, this is a good program to start with. Hopefully in the future I would be able to share deeper insights, but this is all for now!
